An interesting debate has been heating up around whether RAG is already dead in light of new models that offer huge context windows. Meta’s Llama 4 Scout, for example, accommodates 10M tokens. The argument goes that if you can feed that much data into the prompt, you don’t need to connect to external data sources; just include all relevant info in the prompt itself.
It’s a reasonable argument on the surface, but may be premature. A March 2025 research paper tested recall (accuracy) of some of these newer models with big context windows and found that even if a model ostensibly supports context windows in the millions, recall suffered when using more than a fraction, about 2K in most cases.
The problem?
You can see why companies are embracing RAG-enabled inference. The problem is the same one Woodstock organizers faced more than 50 years ago. More users are demanding more of it in a very sudden way.
Specifically, enterprises want:
- Bigger RAG data sets to increase the quantity and quality of data available to AI models
- More complex models to process the data and generate high-quality insights
Neither of these are bad goals. But they both involve a heck of a lot of data, which must be stored somewhere. In today’s world, where model weights and RAG data tend to be stored in memory, that prospect gets extremely expensive quickly.
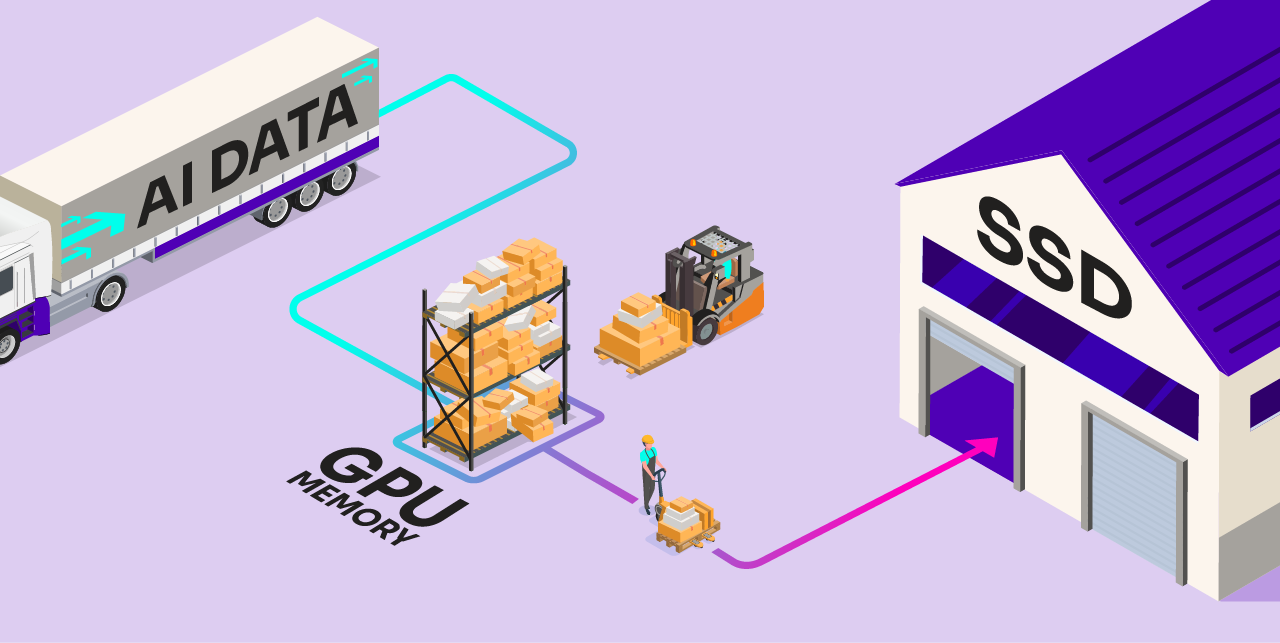
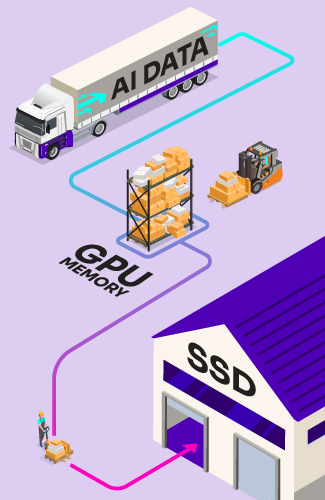
Introducing the SSD offload approach
Working with Metrum AI, Solidigm has pioneered a new way forward. Our approach relies on open-source software components, carefully selected and fine-tuned to work together beautifully, to move a significant amount of data from memory to SSDs during AI inference.
There are two key components:
- RAG data offload: Using DiskANN, a suite of algorithms for large-scale vector data searches, we can relocate part of the RAG data set to SSDs. The primary benefit here is the ability to scale to much larger data sets in a much more cost-effective way.
- Model weight offload: Using Ray Serve with the DeepSpeed software suite, we can move a portion of the AI model itself to SSDs. The main benefit of doing so is enabling more complex models, or multiple models, in a fixed GPU memory budget. For example, we demonstrate the ability to run a 70-billion-parameter model, which typically requires about 160GB of memory, at a reduced peak usage of just 7GB to 8GB.
Key findings
1. Reduced DRAM usage